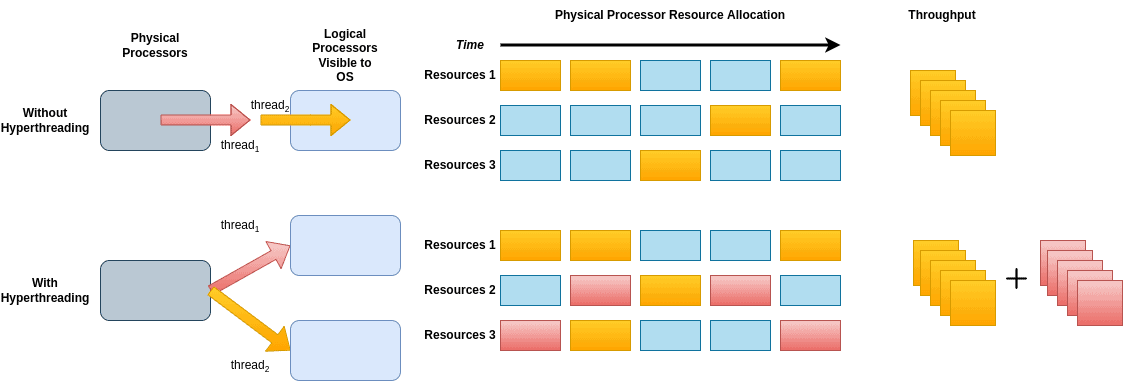
Генеративный искусственный интеллект (Gen AI) стремительно трансформирует способы создания контента, коммуникации и решения задач в различных отраслях. Инструменты Gen AI расширяют границы возможного для машинного интеллекта. По мере того как организации внедряют модели Gen AI для задач генерации текста, синтеза изображений и анализа данных, на первый план выходят такие факторы, как производительность, масштабируемость и эффективность использования ресурсов. Выбор подходящей инфраструктуры — виртуализированной или «голого железа» (bare metal) — может существенно повлиять на эффективность выполнения AI-нагрузок в масштабах предприятия. Ниже рассматривается сравнение производительности виртуализованных и bare-metal сред для Gen AI-нагрузок.
Broadcom предоставляет возможность использовать виртуализованные графические процессоры NVIDIA на платформе частного облака VMware Cloud Foundation (VCF), упрощая управление AI-accelerated датацентрами и обеспечивая эффективную разработку и выполнение приложений для ресурсоёмких задач AI и машинного обучения. Программное обеспечение VMware от Broadcom поддерживает оборудование от разных производителей, обеспечивая гибкость, возможность выбора и масштабируемость при развертывании.
Broadcom и NVIDIA совместно разработали платформу Gen AI — VMware Private AI Foundation with NVIDIA. Эта платформа позволяет дата-сайентистам и другим специалистам тонко настраивать LLM-модели, внедрять рабочие процессы RAG и выполнять инференс-нагрузки в собственных дата-центрах, решая при этом задачи, связанные с конфиденциальностью, выбором, стоимостью, производительностью и соответствием нормативным требованиям. Построенная на базе ведущей частной облачной платформы VCF, платформа включает компоненты NVIDIA AI Enterprise, NVIDIA NIM (входит в состав NVIDIA AI Enterprise), NVIDIA LLM, а также доступ к открытым моделям сообщества (например, Hugging Face). VMware Cloud Foundation — это полнофункциональное частное облачное решение от VMware, предлагающее безопасную, масштабируемую и комплексную платформу для создания и запуска Gen AI-нагрузок, обеспечивая гибкость и адаптивность бизнеса.
Тестирование AI/ML нагрузок в виртуальной среде
Broadcom в сотрудничестве с NVIDIA, Supermicro и Dell продемонстрировала преимущества виртуализации (например, интеллектуальное распределение и совместное использование AI-инфраструктуры), добившись впечатляющих результатов в бенчмарке MLPerf Inference v5.0. VCF показала производительность близкую к bare metal в различных областях AI — компьютерное зрение, медицинская визуализация и обработка естественного языка — на модели GPT-J с 6 миллиардами параметров. Также были достигнуты отличные результаты с крупной языковой моделью Mixtral-8x7B с 56 миллиардами параметров.
На последнем рисунке в статье показано, что нормализованная производительность в виртуальной среде почти не уступает bare metal — от 95% до 100% при использовании VMware vSphere 8.0 U3 с виртуализованными GPU NVIDIA. Виртуализация снижает совокупную стоимость владения (TCO) AI/ML-инфраструктурой за счёт возможности совместного использования дорогостоящих аппаратных ресурсов между несколькими клиентами практически без потери производительности. См. официальные результаты MLCommons Inference 5.0 для прямого сравнения запросов в секунду или токенов в секунду.
Производительность виртуализации близка к bare metal — от 95% до 100% на VMware vSphere 8.0 U3 с виртуализированными GPU NVIDIA.
Аппаратное и программное обеспечение
В Broadcom запускали рабочие нагрузки MLPerf Inference v5.0 в виртуализованной среде на базе VMware vSphere 8.0 U3 на двух системах:
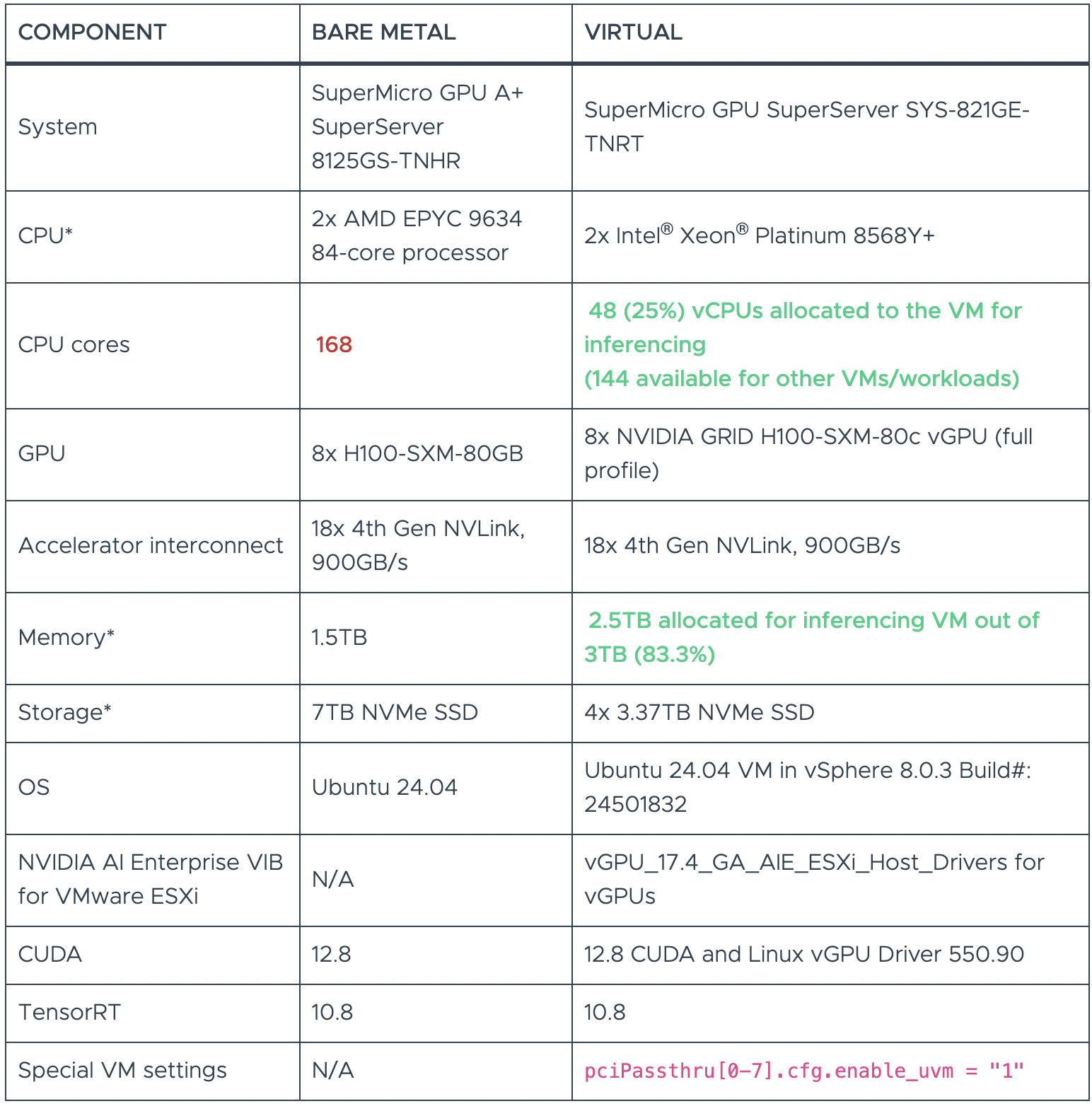
- SuperMicro SuperServer SYS-821GE-TNRT с 8 виртуализированными NVIDIA SXM H100 80GB GPU
- Dell PowerEdge XE9680 с 8 виртуализированными NVIDIA SXM H100 80GB GPU
Для виртуальных машин, использованных в тестах, было выделено лишь часть ресурсов bare metal.
В таблицах 1 и 2 показаны аппаратные конфигурации, использованные для запуска LLM-нагрузок как на bare metal, так и в виртуализованной среде. Во всех случаях физический GPU — основной компонент, определяющий производительность этих нагрузок — был одинаков как в виртуализованной, так и в bare-metal конфигурации, с которой проводилось сравнение.
Бенчмарки были оптимизированы с использованием NVIDIA TensorRT-LLM, который включает компилятор глубокого обучения TensorRT, оптимизированные ядра, шаги пред- и постобработки, а также средства коммуникации между несколькими GPU и узлами — всё для достижения максимальной производительности в виртуализованной среде с GPU NVIDIA.
Конфигурация оборудования SuperMicro GPU SuperServer SYS-821GE-TNRT:

Конфигурация оборудования Dell PowerEdge XE9680:

Бенчмарки
Каждый бенчмарк определяется набором данных и целевым показателем качества. В следующей таблице приведено краткое описание бенчмарков в этой версии набора:

В сценарии Offline генератор нагрузки (LoadGen) отправляет все запросы в тестируемую систему в начале запуска. В сценарии Server LoadGen отправляет новые запросы в систему в соответствии с распределением Пуассона. Это показано в таблице ниже:

Сравнение производительности виртуализованных и bare-metal ML/AI-нагрузок
Рассмотренные SuperMicro SuperServer SYS-821GE-TNRT и сервера Dell PowerEdge XE9680 с хостом vSphere / bare metal оснащены 8 виртуализованными графическими процессорами NVIDIA H100.
На рисунке ниже представлены результаты тестовых сценариев, в которых сравнивается конфигурация bare metal с виртуализованной средой vSphere на SuperMicro GPU SuperServer SYS-821GE-TNRT и Dell PowerEdge XE9680, использующими группу из 8 виртуализованных GPU H100, связанных через NVLink. Производительность bare metal принята за базовую величину (1.0), а виртуализованные результаты приведены в относительном процентном соотношении к этой базе.
По сравнению с bare metal, среда vSphere с виртуализованными GPU NVIDIA (vGPU) демонстрирует производительность, близкую к bare metal, — от 95% до 100% в сценариях Offline и Server бенчмарка MLPerf Inference 5.0.
Обратите внимание, что показатели производительности Mixtral-8x7B были получены на Dell PowerEdge XE9686, а все остальные данные — на SuperMicro GPU SuperServer SYS-821GE-TNRT.

Вывод
В виртуализованных конфигурациях используется всего от 28,5% до 67% CPU-ядер и от 50% до 83% доступной физической памяти при сохранении производительности, близкой к bare metal — и это ключевое преимущество виртуализации. Оставшиеся ресурсы CPU и памяти можно использовать для других рабочих нагрузок на тех же системах, что позволяет сократить расходы на инфраструктуру ML/AI и воспользоваться преимуществами виртуализации vSphere при управлении дата-центрами.
Помимо GPU, виртуализация также позволяет объединять и распределять ресурсы CPU, памяти, сети и ввода/вывода, что значительно снижает совокупную стоимость владения (TCO) — в 3–5 раз.
Результаты тестов показали, что vSphere 8.0.3 с виртуализованными GPU NVIDIA находится в «золотой середине» для AI/ML-нагрузок. vSphere также упрощает управление и быструю обработку рабочих нагрузок с использованием NVIDIA vGPU, гибких соединений NVLink между устройствами и технологий виртуализации vSphere — для графики, обучения и инференса.
Виртуализация снижает TCO AI/ML-инфраструктуры, позволяя совместно использовать дорогостоящее оборудование между несколькими пользователями практически без потери производительности.