
Введение глобальной дедупликации в vSAN для VMware Cloud Foundation (VCF) 9.0 открывает новую эру эффективности использования пространства в vSAN. Применение современных технологий оптимизации хранения позволяет разместить больше данных, чем это физически возможно при традиционных способах хранения, помогая извлечь максимум из уже имеющихся ресурсов.
Однако дедупликация в vSAN для VCF 9.0 — это не просто долгожданная функция в поиске идеального решения для хранения данных. Новый подход использует распределённую архитектуру vSAN и повышает её способность к дедупликации данных по мере роста размера кластера. Кроме того, эта технология отлично сочетается с моделью лицензирования VCF, которая включает хранилище vSAN в состав вашей лицензии.
Благодаря этому глобальная дедупликация vSAN становится более эффективной с точки зрения экономии пространства и значительно доступнее, чем использование VCF с другими решениями для хранения данных. Если рассматривать совокупную стоимость владения (TCO), как описано далее, то использование VCF с vSAN обходится до 34% дешевле, чем VCF с конкурирующим хранилищем в инфраструктуре с 10 000 ядрами. По внутренним оценкам VMware, в этой же модели одна только глобальная дедупликация vSAN может снизить общую стоимость VCF до 4% — что примерно соответствует 10 миллионам долларов! Давайте посмотрим, как особенности глобальной дедупликации vSAN могут помочь сократить расходы на ваше виртуальное частное облако с использованием VCF.
Измерение эффективности
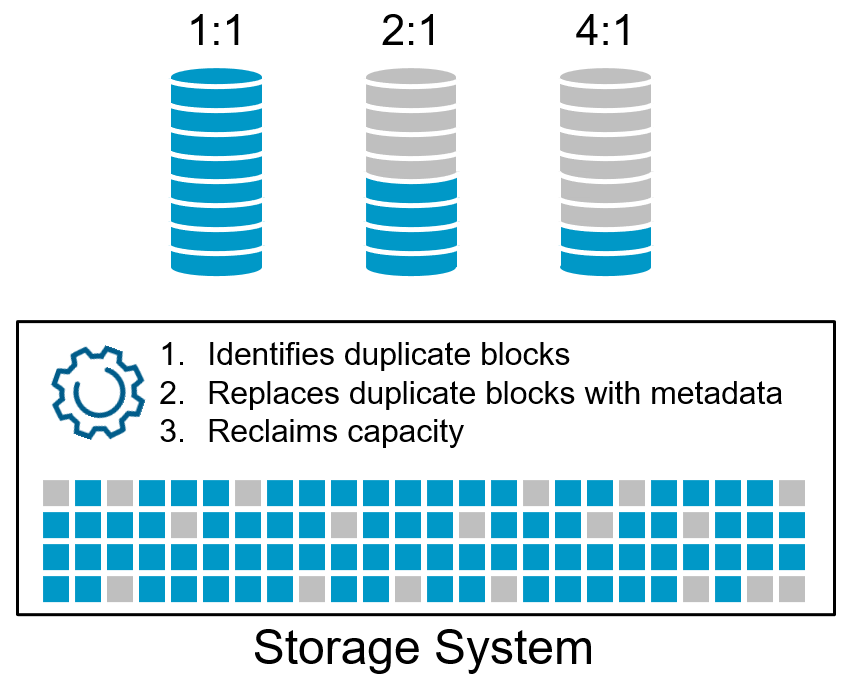
Чтобы правильно понять преимущества дедупликации, необходимо иметь метод оценки её эффективности. Эффективность дедупликации обычно выражается в виде коэффициента, показывающего объём данных до дедупликации и после неё. Чем выше коэффициент, тем больше экономия ёмкости. Такой коэффициент также может отображаться без «:1» — например, вместо «4:1» будет показано «4x».

Хотя коэффициент дедупликации легко понять, к сожалению, системы хранения могут измерять его по-разному. Некоторые показывают эффективность дедупликации только как общий коэффициент «сжатия данных», включая в него такие методы, как сжатие данных, клонирование и выделение пространства под тонкие (thin) тома. Другие могут отображать коэффициенты дедупликации, исключая метаданные и другие накладные расходы, которые не учитываются в измерении. Это важно понимать, если вы сравниваете эффективность дедупликации между системами хранения.
На эффективность дедупликации в системе хранения влияет несколько факторов, включая, но не ограничиваясь:
- Архитектурой системы дедупликации. Системы хранения часто проектируются с учётом компромиссов между эффективностью и затратами, что и определяет разные подходы к дедупликации.
- Размером/гранулярностью дедупликации. Это единица данных, по которой осуществляется поиск дубликатов. Чем меньше гранулярность, тем выше вероятность нахождения совпадений.
- Объёмом данных в пределах домена дедупликации. Обычно, чем больше объём данных, тем выше вероятность, что они будут дедуплицированы с другими данными.
- Сходством данных. Единица данных должна полностью совпадать с другой единицей, прежде чем дедупликация принесёт пользу. Иногда приложения могут использовать шифрование или другие методы, которые снижают возможность дедупликации данных.
- Характеристиками данных и рабочих нагрузок. Данные, создаваемые приложением, могут быть более или менее благоприятны для дедупликации. Например, структурированные данные, такие как OLTP-базы, обычно содержат меньше потенциальных дубликатов, чем неструктурированные данные.
Последние два пункта относятся к рабочим нагрузкам и наборам данных, уникальным для клиента. Именно они часто объясняют, почему одни данные лучше поддаются дедупликации, чем другие. Но при этом архитектура системы хранения играет ключевую роль в эффективности дедупликации. Может ли она выполнять дедупликацию с минимальным вмешательством в рабочие нагрузки? Может ли выполнять её с высокой степенью детализации и в широком домене дедупликации для максимальной эффективности? Глобальная дедупликация vSAN была разработана для обеспечения лучших результатов при минимальном влиянии на рабочие процессы.
Простой внутренний тест продемонстрировал превосходство архитектуры vSAN. На массиве конкурента было создано 50 полных клонов, и столько же — на vSAN. С учётом возможностей дедупликации и сжатия массив показал общий коэффициент сжатия данных 41.3 к 1. vSAN достиг коэффициента 45.27 к 1. Это наглядно демонстрирует впечатляющую эффективность дедупликации vSAN, усиленную сжатием данных для ещё большей экономии. Хотя этот пример не является репрезентативным для показателей дедупликации на произвольных наборах данных, он демонстрирует эффективность дедупликации в vSAN.

Масштабирование ради повышения эффективности
Архитектура системы дедупликации в хранилище играет значительную, но не единственную роль в общей эффективности технологии. Например, домен дедупликации определяет границы данных, в пределах которых система ищет дубликаты блоков. Чем шире домен дедупликации, тем выше вероятность нахождения повторяющихся данных, а значит — тем эффективнее система в плане экономии пространства.
Традиционные модульные массивы хранения, как правило, не были изначально спроектированы как распределённые масштабируемые решения. Их домен дедупликации обычно ограничен одним массивом. Когда клиенту необходимо масштабироваться путём добавления ещё одного массива, домен дедупликации разделяется. Это означает, что идентичные данные могут находиться на двух разных массивах, но не могут быть дедуплицированы между ними, поскольку домен дедупликации не увеличивается при добавлении нового хранилища.
Глобальная дедупликация vSAN работает иначе. Она использует преимущества распределённой архитектуры масштабирования vSAN. В кластере vSAN весь кластер является доменом дедупликации, что означает, что по мере добавления новых хостов домен дедупликации автоматически расширяется. Это увеличивает вероятность нахождения повторяющихся данных и обеспечивает рост коэффициента дедупликации.
На рисунке ниже показан этот пример:
- Слева изображён традиционный модульный массив хранения, обеспечивающий коэффициент дедупликации 6:1. Если добавить ещё один массив, каждый из них по отдельности может обеспечить тот же коэффициент 6:1, но система теряет возможность дедуплицировать данные между массивами.
- Справа показан кластер vSAN из 6 хостов, обеспечивающий коэффициент дедупликации 6:1. По мере добавления новых хостов любые данные, размещённые на этих хостах, входят в тот же домен дедупликации, что и исходные 6 хостов. Это означает, что коэффициент дедупликации будет увеличиваться по мере добавления хостов и роста общего объёма данных.

Использование того, что уже есть
Снижение затрат напрямую связано с увеличением использования уже имеющихся аппаратных и программных ресурсов. Чем выше степень их использования, тем меньше они простаивают и тем дольше можно откладывать будущие расходы.
Модель лицензирования vSAN в составе VCF в сочетании с глобальной дедупликацией vSAN образует выигрышную комбинацию. Каждая лицензия на ядро VCF включает 1 TiB «сырой» ёмкости vSAN. Но благодаря глобальной дедупликации весь объём, который удалось освободить, напрямую работает в вашу пользу!
Например, кластер vSAN из 6 хостов, каждый из которых содержит по 32 ядра, предоставит 192 TiB хранилища vSAN в рамках лицензирования VCF. Если этот кластер обеспечивает коэффициент дедупликации 6:1, то можно хранить почти 1.2 PiB данных, используя только имеющуюся лицензию.

Реальная экономия затрат
Когда хранилище предоставляется как часть лицензии VCF, логично, что затраты на хранение снижаются, поскольку требуется меньше дополнительных покупок. В примере ниже мы сравниваем эффективную цену за 1 ТБ при использовании VCF с конкурентным массивом хранения с дедупликацией для обслуживания рабочих нагрузок уровня Tier-1 и при использовании vSAN с VCF 9.0.
Так как наборы данных представляли собой структурированные данные (SQL), коэффициенты сжатия были весьма скромными. Однако, исходя из модели с 10 000 ядер VCF при предполагаемом уровне загрузки CPU и стоимости лицензирования:
- Эффективная цена за ТБ уже на 14% ниже при использовании только сжатия данных в vSAN.
- А при использовании дедупликации и сжатия в vSAN стоимость хранения (цена за ТБ) становится ниже на 29%.
По собственным оценкам VMware, совокупная стоимость владения (TCO) для VCF может быть снижена до 34%.

А как насчёт вторичного хранилища? Даже когда vSAN использует накопители Read-Intensive TLC и работает в паре с распространённым сторонним поставщиком решений для резервного копирования, итоговая стоимость за 1 ТБ может оказаться ниже, чем при использовании внешнего устройства вторичного хранения.
Для этого сравнения также рассматривалась среда с 10 000 ядер VCF при предполагаемом уровне загрузки CPU и стоимости лицензирования. Даже с учётом дополнительных расходов на стороннее решение для резервного копирования, стоимость хранения в vSAN оказалась на 13% ниже за каждый терабайт.

Если вы заинтересованы попробовать эту функцию в релизе P01 VCF 9.0, вы можете связаться с Broadcom для получения подробной информации через эту форму. В первую очередь внимание будет уделяться клиентам, которые хотят включить её на односайтовых vSAN HCI или кластерах хранения vSAN размером от 3 до 16 хостов с использованием сетей 25GbE или быстрее. На начальном этапе некоторые топологии, такие как растянутые кластеры, а также некоторые сервисы данных, например, шифрование данных at rest, не будут поддерживаться при использовании этой функции.
Итоги
VMware считает, что глобальная дедупликация для vSAN в VCF 9.0 будет не хуже, а скорее всего лучше, чем решения по дедупликации у других поставщиков систем хранения. Учитывая, что клиенты VCF получают 1 TiB сырой ёмкости vSAN на каждое лицензированное ядро VCF, это открывает огромный потенциал: вы можете обеспечить всю необходимую ёмкость хранения, используя только существующее лицензирование, и при этом снизить затраты до минимума.
